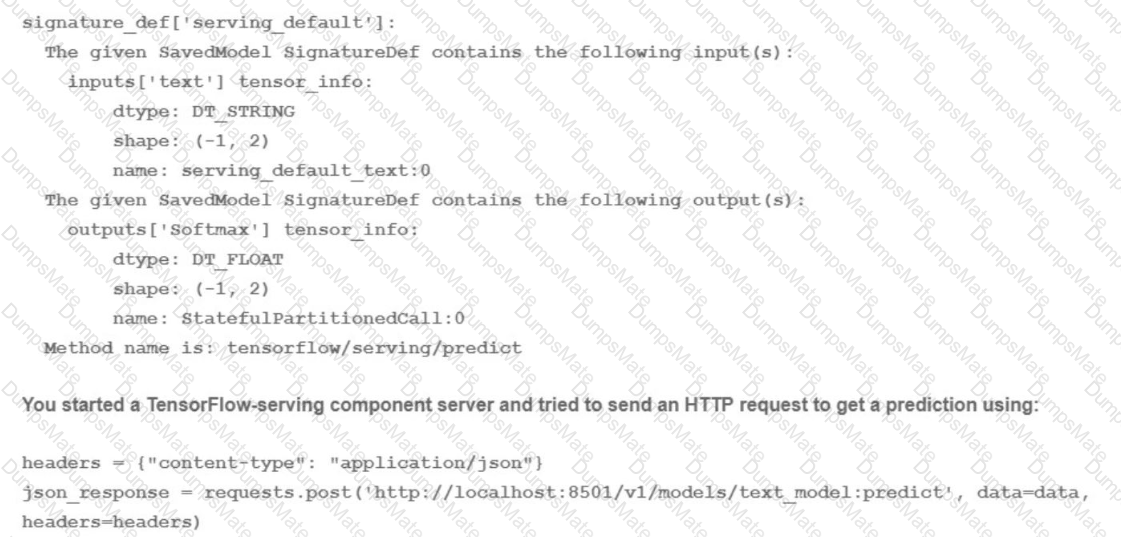
The best option for implementing a batch inference ML pipeline in Google Cloud, using a model that was developed using TensorFlow and is stored in SavedModel format in Cloud Storage, and a historical dataset containing 10 TB of data that is stored in a BigQuery table, is to configure a Vertex AI batch prediction job to apply the model to the historical data in BigQuery. This option allows you to leverage the power and simplicity of Vertex AI and BigQuery to perform large-scale batch inference with minimal code and configuration. Vertex AI is a unified platform for building and deploying machine learning solutions on Google Cloud. Vertex AI can run a batch prediction job, which can generate predictions for a large number of instances in batches. Vertex AI can also provide various tools and services for data analysis, model development, model deployment, model monitoring, and model governance. A batch prediction job is a resource that can run your model code on Vertex AI. A batch prediction job can help you generate predictions for a large number of instances in batches, and store the prediction results in a destination of your choice. A batch prediction job can accept various input formats, such as JSON, CSV, or TFRecord. A batch prediction job can also accept various input sources, such as Cloud Storage or BigQuery. A TensorFlow model is a resource that represents a machine learning model that is built using TensorFlow. TensorFlow is a framework that can perform large-scale data processing and machine learning. TensorFlow can help you build and train various types of models, such as linear regression, logistic regression, k-means clustering, matrix factorization, and deep neural networks. A SavedModel format is a type of format that can store a TensorFlow model and its associated assets. A SavedModel format can help you save and load your TensorFlow model, and serve it for prediction. A SavedModel format can be stored in Cloud Storage, which is a service that can store and access large-scale data on Google Cloud. A historical dataset is a collection of data that contains historical information about a certain domain. A historical dataset can help you analyze the past trends and patterns of the data, and make predictions for the future. A historical dataset can be stored in BigQuery, which is a service that can store and query large-scale data on Google Cloud. BigQuery can help you analyze your data by using SQL queries, and perform various tasks, such as data exploration, data transformation, or data visualization. By configuring a Vertex AI batch prediction job to apply the model to the historical data in BigQuery, you can implement a batch inference ML pipeline in Google Cloud with minimal code and configuration. You can use the Vertex AI API or the gcloud command-line tool to configure a batch prediction job, and provide the model name, the model version, the input source, the input format, the output destination, and the output format. Vertex AI will automatically run the batch prediction job, and apply the model to the historical data in BigQuery. Vertex AI will also store the prediction results in a destination of your choice, such as Cloud Storage or BigQuery1.
The other options are not as good as option D, for the following reasons:
Option A: Exporting the historical data to Cloud Storage in Avro format, configuring a Vertex AI batch prediction job to generate predictions for the exported data would require more skills and steps than configuring a Vertex AI batch prediction job to apply the model to the historical data in BigQuery, and could increase the complexity and cost of the batch inference process. Avro is a type of format that can store and serialize data in a binary format. Avro can help you compress and encode your data, and support schema evolution and compatibility. By exporting the historical data to Cloud Storage in Avro format, configuring a Vertex AI batch prediction job to generate predictions for the exported data, you can perform batch inference with minimal code and configuration. You can use the BigQuery API or the bq command-line tool to export the historical data to Cloud Storage in Avro format, and use the Vertex AI API or the gcloud command-line tool to configure a batch prediction job, and provide the model name, the model version, the input source, the input format, the output destination, and the output format. However, exporting the historical data to Cloud Storage in Avro format, configuring a Vertex AI batch prediction job to generate predictions for the exported data would require more skills and steps than configuring a Vertex AI batch prediction job to apply the model to the historical data in BigQuery, and could increase the complexity and cost of the batch inference process. You would need to write code, export the historical data to Cloud Storage, configure a batch prediction job, and generate predictions for the exported data. Moreover, this option would not use BigQuery as the input source for the batch prediction job, which can simplify the batch inference process, and provide various benefits, such as fast query performance, serverless scaling, and cost optimization2.
Option B: Importing the TensorFlow model by using the create model statement in BigQuery ML, applying the historical data to the TensorFlow model would not allow you to use Vertex AI to run the batch prediction job, and could increase the complexity and cost of the batch inference process. BigQuery ML is a feature of BigQuery that can create and execute machine learning models in BigQuery by using SQL queries. BigQuery ML can help you build and train various types of models, such as linear regression, logistic regression, k-means clustering, matrix factorization, and deep neural networks. A create model statement is a type of SQL statement that can create a machine learning model in BigQuery ML. A create model statement can help you specify the model name, the model type, the model options, and the model query. By importing the TensorFlow model by using the create model statement in BigQuery ML, applying the historical data to the TensorFlow model, you can perform batch inference with minimal code and configuration. You can use the BigQuery API or the bq command-line tool to import the TensorFlow model by using the create model statement in BigQuery ML, and provide the model name, the model type, the model options, and the model query. You can also use the BigQuery API or the bq command-line tool to apply the historical data to the TensorFlow model, and provide the model name, the input data, and the output destination. However, importing the TensorFlow model by using the create model statement in BigQuery ML, applying the historical data to the TensorFlow model would not allow you to use Vertex AI to run the batch prediction job, and could increase the complexity and cost of the batch inference process. You would need to write code, import the TensorFlow model, apply the historical data, and generate predictions. Moreover, this option would not use Vertex AI, which is a unified platform for building and deploying machine learning solutions on Google Cloud, and provide various tools and services for data analysis, model development, model deployment, model monitoring, and model governance3.
Option C: Exporting the historical data to Cloud Storage in CSV format, configuring a Vertex AI batch prediction job to generate predictions for the exported data would require more skills and steps than configuring a Vertex AI batch prediction job to apply the model to the historical data in BigQuery, and could increase the complexity and cost of the batch inference process. CSV is a type of format that can store and serialize data in a comma-separated values format. CSV can help you store and exchange your data, and support various data types and formats. By exporting the historical data to Cloud Storage in CSV format, configuring a Vertex AI batch prediction job to generate predictions for the exported data, you can perform batch inference with minimal code and configuration. You can use the BigQuery API or the bq command-line tool to export the historical data to Cloud Storage in CSV format, and use the Vertex AI API or the gcloud command-line tool to configure a batch prediction job, and provide the model name, the model version, the input source, the input format, the output destination, and the output format. However, exporting the historical data to Cloud Storage in CSV format, configuring a Vertex AI batch prediction job to generate predictions for the exported data would require more skills and steps than configuring a Vertex AI batch prediction job to apply the model to the historical data in BigQuery, and could increase the complexity and cost of the batch inference process. You would need to write code, export the historical data to Cloud Storage, configure a batch prediction job, and generate predictions for the exported data. Moreover, this option would not use BigQuery as the input source for the batch prediction job, which can simplify the batch inference process, and provide various benefits, such as fast query performance, serverless scaling, and cost optimization2.
References:
Batch prediction | Vertex AI | Google Cloud
Exporting table data | BigQuery | Google Cloud
Creating and using models | BigQuery ML | Google Cloud