The customer wants to build a software QA infrastructure using modern big data tools like Spark and Kafka. The goal is to process 50 billion events per day and provide feedback in real-time in less than 5 seconds.
The architect needs to create a FlashBlade configuration to meet the capacity and performance requirements using the following assumptions:
4 RSyslog servers accessing FlashBlade via NFS
6 servers accessing FlashBlade via S3
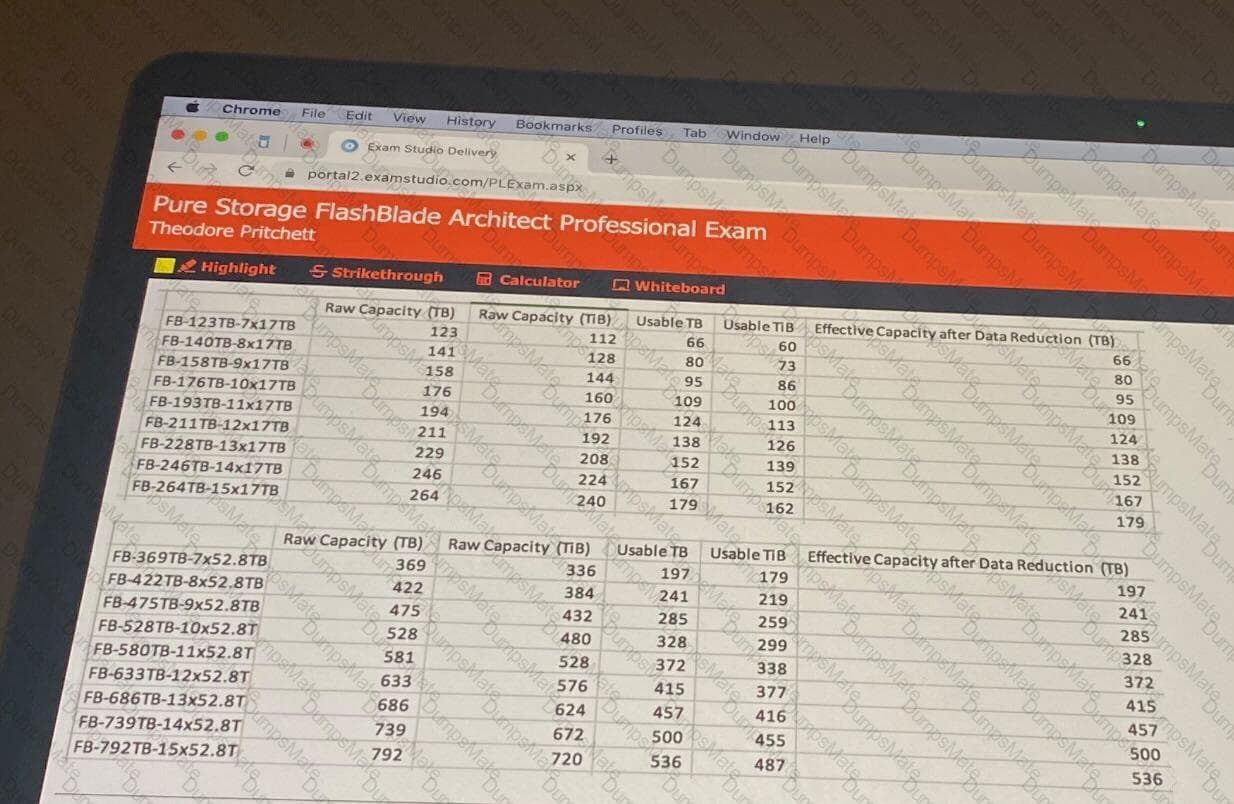
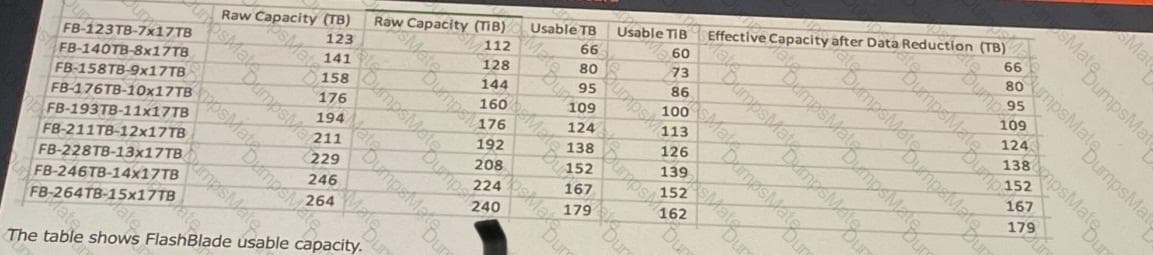
Capacity: 6TB + 18TB + 18TB
Each protocol will create a concurrent write and / or read throughput of 6GB/s
Which configuration should the architect use to meet these requirements?